
Production AI Products, Engineered to Scale.
From LLM-powered apps and RAG systems to autonomous agents and computer vision — we ship AI products to production for startups and enterprises across the United States. Real models, real users, real ROI.
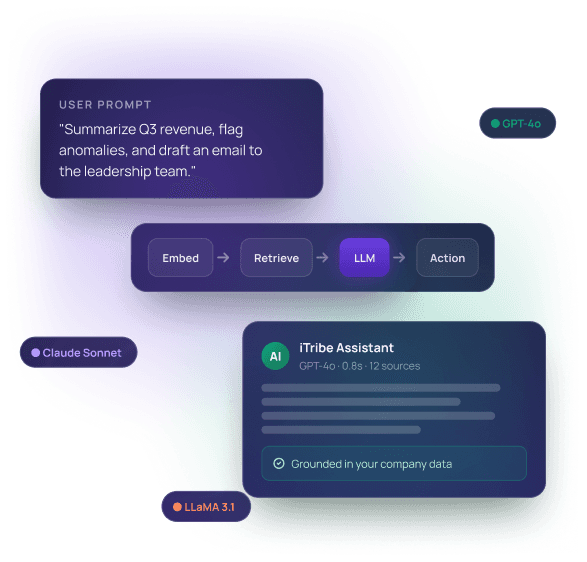
LLM-Powered Applications & Copilots
We build production-grade LLM applications — chat experiences, in-app copilots, content generators, code assistants and structured-output workflows. Every build is grounded in real user research, evaluated against rigorous benchmarks, and engineered for the cost, latency and accuracy your business actually needs.
What You Get
Production LLM application, evaluation harness, prompt registry, observability dashboard, runbook and an in-house team trained on the codebase.
Retrieval-Augmented Generation & Smart Search
We let your users ask plain-English questions of your data — internal docs, contracts, support tickets, knowledge bases, structured records — and get accurate, cited answers. Production RAG: not a notebook demo. Evaluated, observable, governed.
What You Get
Ingestion pipeline, vector index, retrieval API, eval suite (faithfulness / relevance / citation), web UI with sources, ops dashboards.

AI Agents & Multi-Step Workflows
Agents that take real actions — not chat-only demos. We build production agents for sales ops, support automation, document processing, finance and developer tools. Tool-using, error- recovering, observable, and safe by design.
What You Get
Agent runtime, tool registry, observability stack with traces, eval harness, control panel for human approval and full audit trail.

Computer Vision & Image Intelligence
Object detection, OCR, document AI, image moderation and visual search — built on multimodal LLMs and classic CV stacks. We ship vision systems that work on real data, not just curated demos.
What You Get
Vision API, model artifacts, training pipeline, labeling workflow, accuracy dashboards, and SDKs for web & mobile clients.

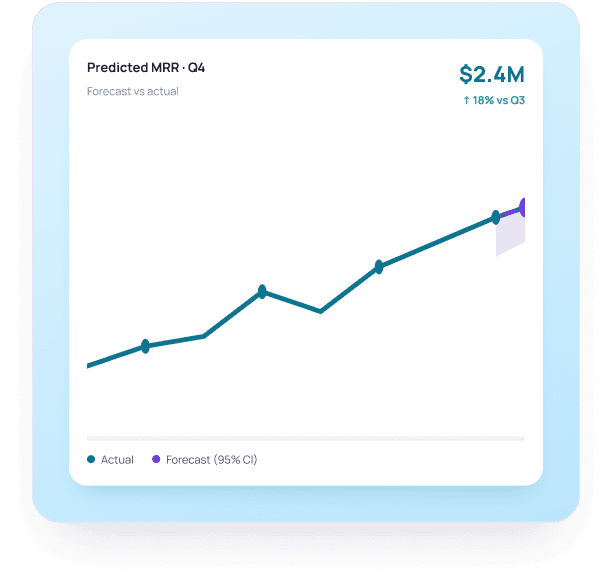
Predictive Analytics & Custom ML Models
Forecasting, scoring, recommendation and anomaly-detection systems — built around your business data. We bring classical ML where it outperforms LLMs and combine the two where it doesn't.
What You Get
Trained model artifacts, feature pipelines, prediction API, model dashboards, drift monitors and quarterly retraining schedule.
Voice AI & Natural Language Processing
Real-time voice agents, transcription pipelines, sentiment analysis, intent classification and call analytics. Built on Whisper, Deepgram, ElevenLabs and your own fine-tuned models when accuracy matters most.
What You Get
Voice agent runtime, transcription pipeline, NLP classifiers, real-time analytics dashboard and integration with your CRM/CCaaS.

Foundation Models & AI Stack
We're model-agnostic — we pick the right one for your latency, cost, accuracy and privacy constraints. Then we build the production scaffolding around it.

OpenAI
GPT-4o · DALL-E · Whisper

Anthropic
Claude Sonnet · Opus · Haiku

Google Gemini
Gemini 1.5 Pro · Flash

Meta LLaMA
LLaMA 3.1 · 8B / 70B / 405B

Mistral AI
Large · Mixtral · Codestral

AWS Bedrock
Multi-model · Governed

Azure OpenAI
Enterprise GPT · Governed

Hugging Face
Open-source · Self-host

LangChain
Orchestration · Agents

NVIDIA
CUDA · Triton · NIM

PyTorch
Training · Fine-tuning

TensorFlow
Serving · TF-Lite
AI in the Wild — What We've Shipped
A snapshot of AI products we've put in production for US clients across SaaS, fintech, healthcare, e-commerce and operations.
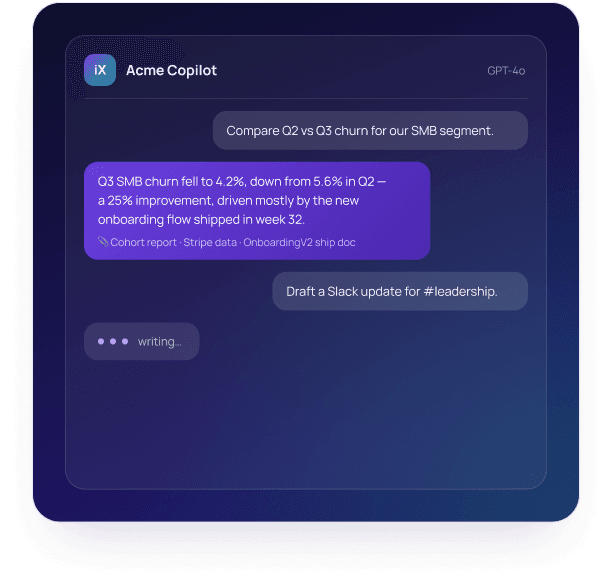
In-Product Copilot for a B2B Workflow Tool
GPT-4o-powered assistant that understands the user's data, drafts content and triggers actions inside the app. Replaced 60% of help-doc traffic with one-shot answers.
Document Intelligence for Loan Underwriting
Multimodal LLM extracts structured data from W-2s, 1099s and bank statements, runs validations and generates a draft underwriting memo.
HIPAA-Compliant Clinical Note Summarizer
Self-hosted LLaMA pipeline turns 90-minute visit transcripts into structured SOAP notes — never leaves the customer's VPC.
AI-Generated Product Descriptions & SEO
RAG-augmented content generation pipeline that writes brand-on, SEO-optimized product copy at scale — across 18 languages.
Predictive Demand & Routing Engine
Time-series forecasting plus an LLM-driven exception handler that re-routes shipments when conditions change.
Voice Agent for Tier-1 Support Calls
Real-time voice agent on Whisper + GPT-4o handles refunds, order lookups and FAQ — escalates the rest with full context.
Our Five-Stage AI Delivery Process
Each AI engagement runs through the same disciplined cycle — calibrated to ship things that work, not demos that don't.
Discover & Define
Map the use case, success metrics, data sources, constraints and risk profile. Prove there's actually an AI problem.
Prototype
2-week prototype using the simplest model that could possibly work. Real data, real users, real evaluation.
Productionize
Eval harness, observability, guardrails, CI/CD, cost telemetry. The unsexy work that makes AI products actually run.
Launch
Staged rollout with feature flags, A/B testing and a public-facing changelog so users know what changed.
Iterate
Monitor drift, retrain, re-route between models. AI products are products — they need ongoing care.
Questions Founders & Product Leaders Ask
The questions we hear most before kicking off an AI engagement — answered honestly, without the sales pitch.
How long does an AI MVP typically take?
For most LLM-app or RAG MVPs, 2-4 weeks to working prototype and 8-12 weeks to production launch. Custom-trained or fine-tuned models add 4-6 weeks for data prep and evaluation.
Which model providers do you work with?
OpenAI, Anthropic, Google (Gemini), Meta (LLaMA), Mistral, AWS Bedrock, Azure OpenAI and Hugging Face. We also self-host open models when privacy, cost or latency demands it.
Can the model run inside our infrastructure?
Yes. We deploy self-hosted LLaMA, Mistral and other open models inside your AWS / GCP / Azure VPC, on-prem GPUs or air-gapped environments — fully under your control.
Are you HIPAA / SOC 2 / PCI-aware?
Yes. We've shipped HIPAA-compliant clinical AI, PCI-aligned fraud-detection and SOC 2-ready SaaS copilots. We pair you with engineers who've shipped under each framework.
How do you measure if the AI actually works?
Every engagement ships with an evaluation harness — golden test sets, human-graded eval, faithfulness/relevance/citation metrics for RAG, and online A/B tests against the legacy baseline.
What does an AI engagement cost?
Discovery sprints from $15k. Production AI MVPs from $60k-$180k depending on scope. Ongoing AI retainers from $18k/month. Detailed estimate within 48 hours of a discovery call.
Do you fine-tune custom models?
Yes — supervised fine-tuning, RLHF/DPO, LoRA adapters and full retraining when warranted. We always start with prompting and RAG; we fine-tune only when evaluation shows it's actually needed.
What about hallucinations and AI safety?
We treat hallucination as an engineering problem. Every AI product ships with retrieval grounding, citation enforcement, confidence-aware refusal, output validation, PII redaction and human-in-the-loop checkpoints where the cost of being wrong is high.
Ready to ship AI that actually works?
Tell us about your use case. You'll get a fixed-scope estimate, recommended model stack and a 12-week production plan within 48 hours.
WHAT YOU'LL GET IN 48 HOURS
- Fixed-scope project estimate
- Recommended model & stack
- 12-week production plan
- Eval criteria & success metrics
- No obligation, no sales pressure